

Predictive maintenance (PdM) is an essential approach for improving equipment performance and reliability in various industries. This is particularly crucial in sectors like oil and gas, chemicals and power generation, where equipment operates under harsh operating conditions, resulting in a higher failure rate, reduced lifetime and increased operational costs. By leveraging modern condition monitoring and advanced data analytics techniques, PdM systems track key health indicators such as temperature, leakage and vibration, enabling early identification of potential failures and prediction of maintenance requirements. This proactive approach minimizes the loss of revenue or operations due to unplanned disruptions.
In 2021, it was reported by BCG Global that 42.5% of companies in the United States allocated 21%-40% of their operational budgets for maintenance. A McKinsey & Company study shows PdM can lower machine downtime by 30%-50% and extend equipment life by 20%-40%. Additionally, insights gained from PdM practices can promote sustainability by helping increase energy efficiency in equipment operation and minimizing leaks and emissions to the environment.
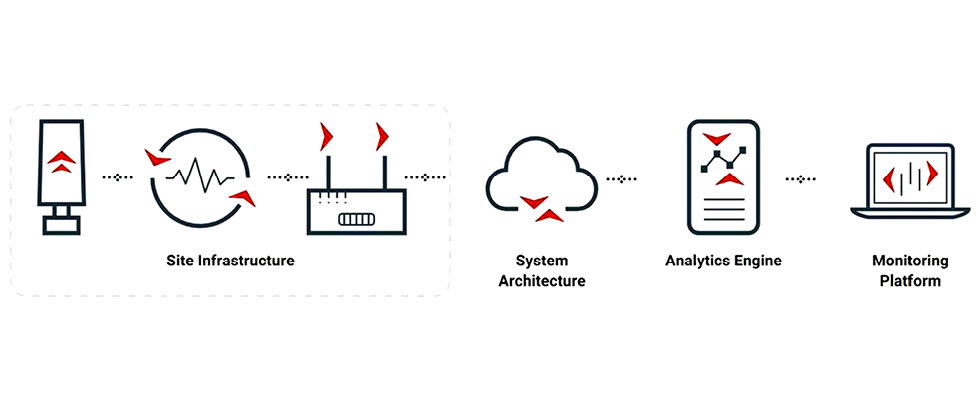
Characteristics of Good Data & Field Challenges
The performance of PdM algorithms relies heavily on the data used to develop them. Robust PdM systems benefit from a wide range of comprehensive data, such as operational data (e.g., temperature, pressure, vibration), maintenance logs, environmental data and failure mode and effects analysis (FMEA) information.
For PdM data to be considered “good” data, it must meet the following key characteristics: relevant, granular, high-quality and diverse. Relevance is directly tied to equipment’s specific operation and conditions, accurately providing an indication of potential failure mode. Granularity, such as high-frequency sensor readings, allows the system to detect subtle changes in equipment condition or performance and ensures that no significant signals are missed between data collection periods. High-quality data is accurate, consistent and complete without noise or gaps. Finally, diversity in data refers to collecting information from various sources and conditions. This variety provides a more comprehensive understanding of equipment health and enables the development of an advanced model that provides a holistic view of asset performance through integration of multiple data sources.
However, obtaining “good” data from field operation faces several challenges. First, the installation of sensors and network infrastructure for data collection and transmission requires high upfront costs, while the storage and processing of the vast amount of collected data demands a long-term financial commitment. Privacy and security issues should not be overlooked, as sensitive or proprietary data may be restricted from sharing, leading to underutilization of existing data. Traditional decentralized IT and data management systems create data silos, further limiting the utilization of data. Additionally, limited sensor coverage, faulty sensors and inconsistent data undermine algorithm accuracy and effectiveness. Lastly, certain real-world failure incidents are often very rare and challenging to capture, as industrial equipment is designed for reliable, long-term operation. Frequency of failures is also greatly reduced by overly conservative maintenance actions such as premature part replacement and unnecessary redundancy, leading to inefficient plant operation. After data is collected, challenges remain in effective data management, where a thorough understanding and organization of the data is crucial before utilizing it to develop reliable algorithms.
Overcoming Field Data Limitations
To address the challenges of obtaining operational data from real-world operations, four alternative approaches with distinct benefits are available: lab testing, high-fidelity physics models, transfer learning and generative AI. While other types of data, such as environmental data, FMEA and maintenance logs are also important, these approaches primarily focus on supplementing operational data.
Lab Testing
Lab testing provides a controlled environment where operating variables like pressure, temperature and flow rates can be precisely manipulated to replicate various operating conditions and failure scenarios while collecting data when the system undergoes failure symptoms and performance degradation.
For example, mechanical seals on pumps can be subjected to dry running conditions simulated through restricting cooling flush flow or adding heat to the seal chamber. This lab test produces data related to dry running, such as vibration patterns, temperature anomalies or pressure fluctuations, which are collected and used to develop PdM algorithms to detect or predict a dry running event.
Moreover, lab testing allows strategic sensor placement, ensuring sensors are positioned optimally to improve
relevance of data, which improves PdM algorithm accuracy. Another key advantage is its ability to accelerate failure processes that can take years to occur in real-world situations, allowing faster data collection and a quicker algorithm development cycle.
However, lab testing has its limitations. It can be costly, requiring specialized equipment and skilled personnel. It can also be time-consuming, especially for complex systems that are difficult to design and build or when strict safety regulations must be followed.
Additionally, lab testing may be able to simulate only specific failure modes and environments, limiting the range of data generated and not fully covering all targeted failure modes. As a result, PdM models developed using lab data may underperform in real-world environments, potentially overfitting or failing to adapt to unseen conditions. To mitigate this, lab data can be supplemented with field data to ensure PdM models remain robust and adaptable to real-world operations.
High-Fidelity Physics Models
Developed from foundational principles such as fluid dynamics and heat transfer, high-fidelity physics models simulate equipment performance under a wide range of conditions. By defining and parameterizing the key physical properties of a target system and operating conditions, these models offer valuable insights into how equipment behaves and deteriorates under mechanical, thermal, hydraulic and chemical stresses.
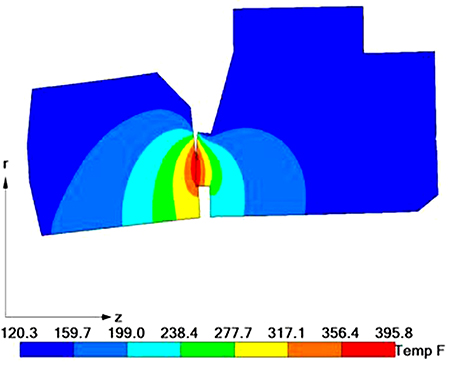
Computational fluid dynamics (CFD), finite element analysis (FEA) and multiphysics modeling are the enabling techniques to simulate complex system behaviors and failure modes that are difficult to duplicate in the lab. For
example, CFD can replicate the effects of cavitation on the impeller of a pump, helping not only identify early signs of cavitation for PdM systems but also detect erosion-prone locations and improve impeller design. FEA can assess how pressure fluctuations degrade valve performance over time via material fatigue, and this provides valuable data that can be used to develop a model for estimating valve replacement timing as well as enhancing design and material selections.
Although these models provide quality data and substantial insights, they are computationally expensive, limiting their use in continuous monitoring. This issue can be mitigated by developing a surrogate model. Machine learning techniques, such as neural networks, can be employed to develop a surrogate model trained on data generated by a high-fidelity physics model. The resulting trained model is computationally lighter to execute while still imitating the physics-based model.
Another shortcoming of high-fidelity physics models is their lack of natural variability and noise, which are common in real-world data. Several data augmentation techniques might bring variability to increase the robustness of the models. Noise injection techniques, for example, can add random noise to data generated from the high-fidelity physics model to replicate background noise, therefore training the model to capture actual failure signals from noise-containing data. While data rotation or shifting adds more variants that expose the model to multiple angles of the same dataset, random sampling and data scaling allow the model to replicate varied operating settings. These data augmentation techniques enable the physics-based models to be more resilient, improving the accuracy and adaptability of PdM algorithms in real-world environments.
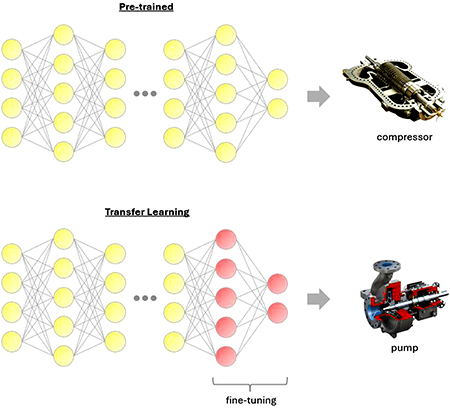
Transfer Learning
Transfer learning is particularly effective when there is limited data on certain machinery or a specific failure mode but sufficient data available for similar machinery or failure modes. Transfer learning uses pretrained models initially developed for similar systems and fine-tunes them with a minimal amount of additional data. In this manner, PdM systems apply existing knowledge to new equipment, thereby lowering the demand for comprehensive domain-specific datasets. For instance, a model trained for anomaly detection in compressors may later be fine-tuned and applied to pumps since the two systems share similarities in design and operation. Both compressors and pumps may exhibit comparable vibration patterns under situations like load imbalances or pressure changes. The more similar the systems are, the more efficiently insights from compressor data can be transferred, reducing the need for additional data during fine-tuning.
Despite its advantage, transfer learning has significant limitations. Substantial differences in operating conditions or failure modes between source and target systems can lead to poor generalization of the model. Ensuring task similarity is a key prerequisite of successful transfer learning. Without it, the model may struggle to adapt effectively. Moreover, negative transfer can happen, where fine-tuning produces lower performance than training a new model from scratch. Furthermore, biases present in the original source can propagate to the new model, undermining the model’s detection and forecast accuracy. Thorough evaluation and tuning are essential to overcome these risks and ensure effective transfer learning implementation.
Generative AI
Generative AI (GenAI) has become a valuable technique for developing PdM algorithms, especially when real-world failure data are scarce. There is currently active research focused on using generative adversarial networks (GANs), a type of GenAI technique, to generate synthetic data that compensates for the naturally limited data available for industrial applications. GANs consist of two neural networks: a generator and a discriminator.
The generator uses deep learning techniques to create synthetic data by learning patterns and features from a real dataset. Meanwhile, the discriminator assesses whether the data is real or generated by comparing it to the actual dataset. Through repeated rounds of competition, the generator improves its ability to fool the discriminator, while the discriminator becomes better at identifying fake data. As a result, the generator produces increasingly realistic failure data.
Despite their ability to generate new data, GANs still require baseline real-world data to learn the patterns inherent to the system being modeled. This allows GANs to understand system dynamics and identify key features and correlations. By leveraging this baseline data, GANs can augment existing datasets by creating variations of existing failure scenarios and even generating entirely new failure scenarios. This augmentation enhances the robustness of PdM algorithms by improving model accuracy and generalizability.
PdM remains an evolving field, with advancements in communication and computational capabilities offering new possibilities. While the industry may have ample data, it frequently lacks the relevant, granular, high-quality and diverse data needed to build truly effective predictive maintenance systems due to various administrative, technical and financial issues. This article proposed four approaches to supplement field data. It is very important to preserve data created via these methods in a structured manner so they can act as a positive feedback loop in creating a resource for algorithm creation.
However, it is important to emphasize that these methods are designed to supplement but not replace real-world data. Ongoing efforts to collect and improve real-world data remain essential for more accurate and robust PdM models. Human expertise continues to play a key role in interpreting complex data, understanding the context and reviewing and fine-tuning the models.
